Overview
Contents
Overview¶
Python is great for many reasons including:
High−level (so you can focus on your problem).
Clean, readable, and efficient.
Easy and fun to learn.
Dynamic.
Fast to write and test code.
Less code.
Flexible.
Interactive.
Great support
Open source.
Vast range of libraries.
Huge number of users.
However, sometimes it can be slow. Often this isn’t an issue. Though when it is, it’s useful to know how to speed it up.
That’s what this workshop is all about.
Hang on, don’t optimise too early¶
There are trade-offs when you pursue faster code. For example, it may become more complex, use more memory, become less readable. This is in addition to the optimisation process taking time and effort. So, before jumping into optimising code, check that:
The code is correct?
Have you tested it?
Does it have documentation?
Is optimisation really needed?
Have you profiled the code?
If optimisation is needed, then first:
Have you tried more suitable algorithms and data structures?
Have you tried vectorisation?
Have you tried compiling the code?
If that’s still not enough, then:
Try parallelisation.
Try offloading the work to accelerators.
Plot idea from Dask-ML.
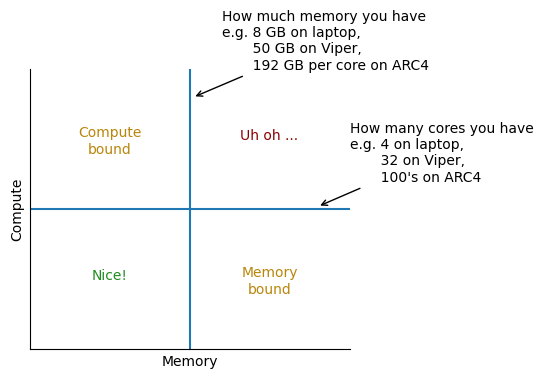
How fast could it go?¶
It’s useful to know how code speed is measured. Miles per hour? Bits per second?
The speed of code doesn’t have specific units like that. For one reason, this is because computers vary a lot.
Instead, it’s normally measured in order of operations (O) per element (n).
This means how many operations are needed as the number the elements gets bigger.
The order of operations is called Big O notation.
The operations are given as the largest order of a polynomial, ignoring any constants.
For example, O(2n2 + 3n) would just become O(n2).
This becomes important when the number of elements is large.
It’s often measured for a typical case.
Constant time means per machine operation.
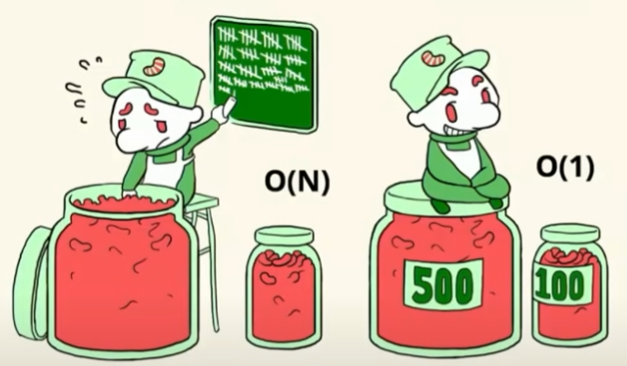
A nice example from Ned Batchelder’s PyCon talk is for counting beans in a jar.
Method 1: If you count each bean one by one as you pick it out of the jar, then this would be an O(n) time operation. So for a new jar of beans, you’ll have to repeat this operation for every bean in the jar. Think of making tally marks for each one.
Method 2: You have a label on the front of the jar, which tells you how many beans are in it. For this method, no matter how many beans are in there, the time of the operation stays the same at O(1).
Memory is measured in the same way.
Both of these two measurements together represent the time-space complexity of your code.
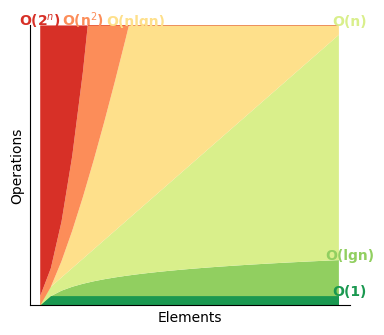
You can compare the lines for the different time-space complexities on the plot below:
Note, logs here are base 2.
Plot idea from Big O Cheat Sheet.
To follow along¶
Option 1 (recommended) - Run on Google Colab:
Click on the Colab button within each Jupyter notebook to run there.
Option 2 - Run locally:
a. Clone this GitHub repository:
git clone git@github.com:lukeconibear/swd6_hpp.git
cd swd6_hpp
b. Copy this conda environment:
conda env create --file environment.yml
conda activate swd6_hpp
# create the kernel for jupyter
python -m ipykernel install --user --name swd6_hpp --display-name "swd6_hpp"
c. Open Jupyter Lab:
jupyter lab